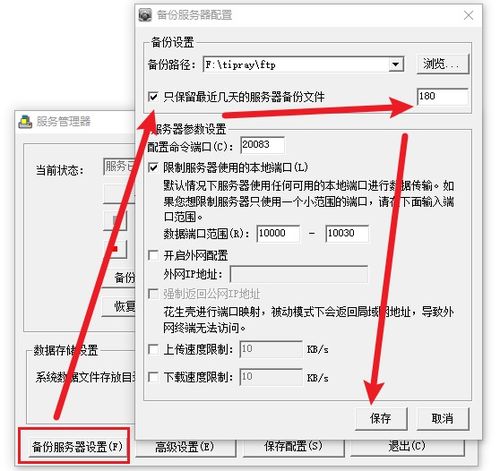
云上应用系统数据存储架构演进 数据处理与存储支持服务的升级之路
随着云计算技术的普及与深化,云上应用系统的数据存储架构正经历一场深刻的变革。从传统的单一数据库到如今多样化、分布式、智能化的存储体系,其演进历程不仅反映了技术发展的脉络,更体现了业务对数据处理与存储支持服务日益增长的需求。
第一阶段:集中式存储与初步云化
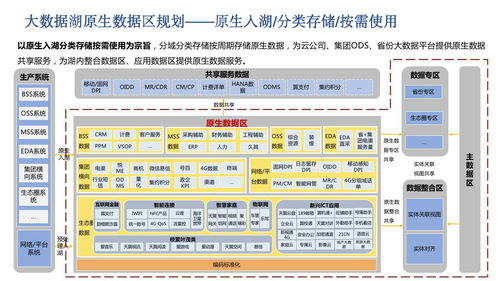
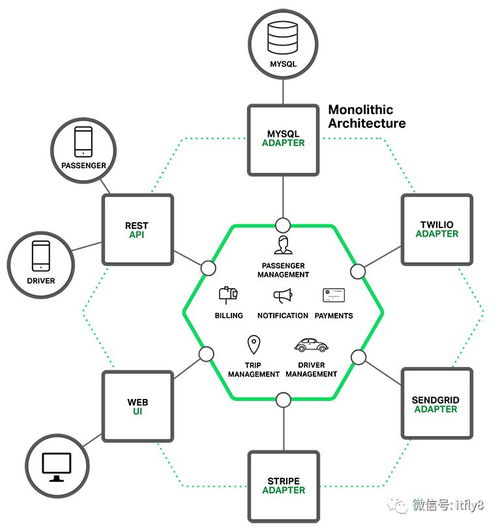
早期应用多采用集中式的关系型数据库(如MySQL、Oracle),数据存储于单一节点,通过主从复制保障可用性。上云初期,主要是“搬迁”思维,将本地数据库整体迁移至云服务器或托管型数据库服务(如RDS),利用云平台的弹性伸缩与基础运维能力,但架构本质未变。数据处理以批量ETL和事务处理为主,存储支持服务相对单一。
第二阶段:分布式架构与存储解耦
随着应用规模扩大,高并发和海量数据挑战凸显。架构开始向分布式演进:
1. 数据库分层与分库分表:读写分离、垂直拆分(按业务)与水平拆分(按数据维度)缓解单点压力。
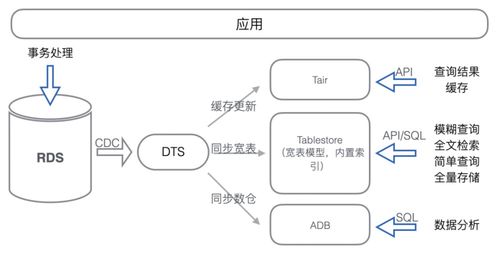
2. 引入NoSQL与专用存储:为应对非结构化数据、高吞吐读写(如Redis缓存、MongoDB文档库)或时序数据(如InfluxDB),存储方案走向多元化。
3. 对象存储的普及:OSS/COS等对象存储成为图片、视频、日志等静态资源的标配,实现存储与计算彻底解耦。
此阶段,数据处理开始流批兼顾,存储支持服务需管理多种异构存储组件。
第三阶段:云原生存储与湖仓一体
云原生理念推动存储架构深度重构:
1. 托管与Serverless数据库:云数据库(如Aurora、PolarDB)提供近乎无限的扩展性与自动管理能力。Serverless数据库(如FaunaDB、Azure Cosmos DB Serverless)实现按实际使用量计费,成本更优。
2. 存算分离成为主流:计算节点与存储节点独立弹性伸缩,如基于HDFS/OSS的数据湖架构,或Snowflake、Databricks引领的湖仓一体(Lakehouse)模式,在数据湖的灵活性上融合数据仓库的管理与性能。
3. 数据处理实时化与智能化:流处理框架(Flink、Spark Streaming)支持实时分析;AI与存储结合,实现智能分级存储(冷热温数据自动迁移)、智能索引与查询优化。
存储支持服务演进为统一的数据平台,提供数据集成、治理、安全与全生命周期管理。
第四阶段:智能化与边缘协同的下一代架构
前沿探索已现端倪:
1. AI原生存储:存储系统内置AI能力,实现预测性性能调整、异常检测与自修复。
2. 统一语义层与数据网格:通过数据网格(Data Mesh)理念,将存储架构从集中式平台转向面向领域的分布式数据产品,强调域自治与标准化接口。统一语义层(如OneHouse、StarRocks)尝试在多样存储之上提供统一查询体验。
3. 边缘存储与云边协同:IoT与5G驱动下,边缘节点进行数据预处理与临时存储,云中心做持久化与全局分析,形成协同的分层存储体系。
数据处理趋向实时智能与边缘预处理并重,存储支持服务需跨越云边环境,实现全局数据一致性与可观测性。
数据处理与存储支持服务的核心演进
纵观全程,支持服务的关键转变在于:
- 从运维到赋能:从保证存储可用性,转向提供数据接入、开发、治理、服务与价值挖掘的全链路平台能力。
- 从孤立到融合:通过统一元数据管理、数据目录与安全策略,整合异构数据源,打破孤岛。
- 从固定到自适应:利用云的可观测性与自动化,实现存储性能、成本与安全策略的动态优化。
- 从中心到分布式:支持多云、混合云乃至边缘场景下的数据存储与流动。
###
云上数据存储架构的演进,是一条从集中到分布、从固定到弹性、从单一到智能、从中心到边缘的持续进化之路。其核心驱动力始终是业务对数据价值挖掘日益迫切的渴望。未来的架构必将继续向着更智能、更融合、更无处不在的方向发展,而数据处理与存储支持服务,将作为关键基石,赋能应用系统在数据洪流中稳健航行,洞察先机。
如若转载,请注明出处:http://www.nuchonglianmeng.com/product/59.html
更新时间:2026-05-30 14:06:48